ウェブフロント
- angular
- corewebvitals
- editorconfig
- gatsby
- hls
- html
- javascript
querySelectorAllで取得した要素は配列ではないらしい
JavaScript 配列内のオブジェクトの更新ってどうする?
デバッグ関数とかnullチェック関数をutil/index.tsにおいとけば楽なことに今頃気づいた。
ブラウザからジャイロセンサーを使ってみる
JS 画像のアップロード、プレビュー機能を実装
「数値から各桁の値を取り出す処理」って言われたら数学的な処理が一番に思い浮かぶけど、JSならそんなことなかった。
Callback時代の関数をPromise化する
個人的実装されてほしいECMA Script Proposal
JavaScriptのprototypeを使う
音声をなみなみさせる
AudioWorkletとAudioWorkletProcessorを使って音声のビジュアライゼーション
- next
- nuxt
- playwright
- prettier
- react
- reactnative
- tensorflowjs
- tools
- typescript
- wasm
- websocket
- ポエム
- 開発環境
サーバー
その他
DL初挑戦 pytorchを使ってSTL10の学習させてみたけどむずすぎた
はじめに
参加しているある団体のDeepLearningハッカソンに参加しまして, STL10っていう画像セットとpytorchを使ったクラス分類をしました.
DL楽しいな!って思ったんだけど, pythonむずすぎたわ..
DL楽しいな!って思ったんだけど, pythonむずすぎたわ..
コード
まず前処理の定義をします.
訓練画像にはランダムにFlipさせて水増しした後, テンソルにしたり標準化させたりします.
検証画像は水増しする必要ないのでFlipは行いません.
訓練画像にはランダムにFlipさせて水増しした後, テンソルにしたり標準化させたりします.
検証画像は水増しする必要ないのでFlipは行いません.
transform_train = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])つぎにSTL10の画像データを読み込みます.
trainset = datasets.STL10('./data', split='train', download=True, transform=transform_train)
testset = datasets.STL10('./data', split='test', download=True, transform=transform_test)読み込んだ画像をバッチサイズとか適用させながら分けていきます.
バッチサイズはなんか適当です..
10でやってたら精度がガタガタだったので20に増やしましたー.
バッチサイズはなんか適当です..
10でやってたら精度がガタガタだったので20に増やしましたー.
# 5000枚
train_loader = DataLoader(
trainset, batch_size=20, shuffle=True,
num_workers=4, drop_last=True,
)
# 8000枚
test_loader = DataLoader(
testset, batch_size=20, shuffle=False,
num_workers=4, drop_last=False,
)今回分類するクラスです.
classes = ('plane', 'bird', 'car', 'cat', 'deer', 'dog', 'horse', 'monkey', 'ship', 'truck')ネットワークにはVGG16っていうやつを使ってfine-tuningします.
pretrained=Trueにすると予め学習している重みを使ってくれます.net = models.vgg16(pretrained=True)
元のままだと1000個に分類されちゃうのでクラスタリングのとこの最後の層を入れ替えます.
net.classifier[6] = nn.Linear(in_features=4096, out_features=10, bias=True)損失関数と最適化関数を定義します.
さいしょAdamつかったら酷かった()ので大人しくSGDつかいます..
ハイパーパラメータは適当です(特に根拠はないです).
さいしょAdamつかったら酷かった()ので大人しくSGDつかいます..
ハイパーパラメータは適当です(特に根拠はないです).
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9, weight_decay=0.005)あとは学習用コードと, 検証用コードをどんっ!
# GPU仕様に変更
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net = net.to(device)
# 学習結果の保存用
history = {
'train_loss': [],
'test_loss': [],
'test_acc': [],
}
# 学習する
for epoch in range(10):
running_loss = 0.0
# 学習開始
net.train()
for i, data in enumerate(train_loader, 0):
inputs, labels = data
inputs, labels = Variable(inputs), Variable(labels)
# GPU仕様に変更
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = net(inputs)
# 損失の計算
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.data
if i % 50 == 49:
print('[%d, %5d] loss: %.3f' % (epoch+1, i+1, running_loss / 100))
if (i == 249):
history['train_loss'].append(float(running_loss / 100))
running_loss = 0.0
# テストデータで検証
net.eval()
correct = 0
total = 0
test_loss = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images = Variable(images)
images = images.to(device)
labels = labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
loss = criterion(outputs, labels)
test_loss += loss.item()
print('test loss: %.3f' % (test_loss / len(test_loader)))
print('test Accuracytest: %.3f %%' % (100 * correct / total))
history['test_loss'].append(float(test_loss / len(test_loader)))
history['test_acc'].append(float(100 * correct / total))
print('Finished Training')いい感じのときはこんなですー.
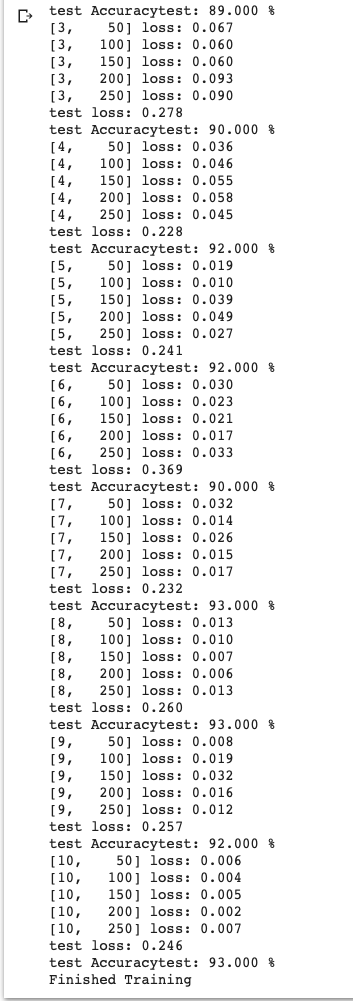
最後にてすと!
correct = 0.0
total = 0.0
for data in test_loader:
images, labels = data
images = Variable(images)
images = images.to(device)
labels = labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
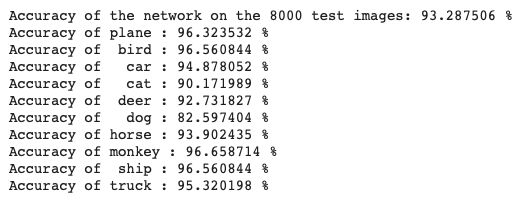
print('Accuracy of the network on the 8000 test images: %3f %%' % float(100 * correct / total))
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
for data in test_loader:
images, labels = data
images = Variable(images)
images = images.to(device)
labels = labels.to(device)
#print("images type : ", type(images))
#print("images.shape : ", images.shape)
# 学習
outputs = net(images)
# 一番確率が高いの
_, predicted = torch.max(outputs.data, 1)
c = (predicted == labels).squeeze()
for i in range(10):
label = labels[i]
class_correct[label] += c[i]
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %3f %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))まあまあいいんじゃないですか..
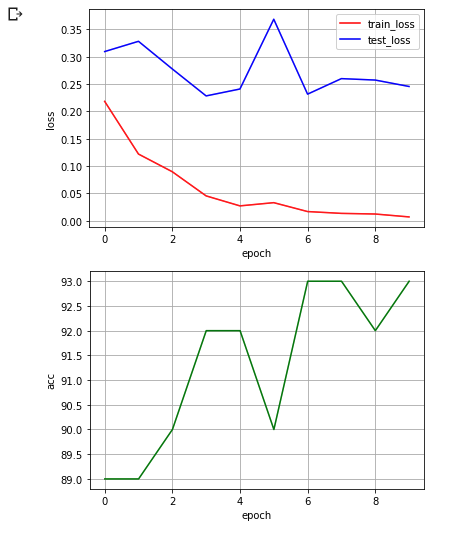
一応グラフにもしてみましたー.
まぁきれいじゃないけど。。
まぁきれいじゃないけど。。
おわりに
学習したモデルを使って自分家のねこの画像で検証させたら ねこ! ってなってたので満足です!(は
コードはめっちゃ汚いですけど, なんとかできたので次はもう少し綺麗に書きます..
ちなみに精度96%ぐらいでてた友達はモデルいっぱい使ってアンサンブル学習させてましたね.
たぶんそれが最強そうです. 次やってみます.
たぶんそれが最強そうです. 次やってみます.
初挑戦にしてはがんばったでしょ!
python嫌い!!!!!!!!!!!!!!!!!!!!
Thanks you for reading.