ウェブフロント
- angular
- corewebvitals
- editorconfig
- gatsby
- hls
- html
- javascript
querySelectorAllで取得した要素は配列ではないらしい
JavaScript 配列内のオブジェクトの更新ってどうする?
ブラウザからジャイロセンサーを使ってみる
デバッグ関数とかnullチェック関数をutil/index.tsにおいとけば楽なことに今頃気づいた。
JS 画像のアップロード、プレビュー機能を実装
「数値から各桁の値を取り出す処理」って言われたら数学的な処理が一番に思い浮かぶけど、JSならそんなことなかった。
Callback時代の関数をPromise化する
個人的実装されてほしいECMA Script Proposal
JavaScriptのprototypeを使う
音声をなみなみさせる
AudioWorkletとAudioWorkletProcessorを使って音声のビジュアライゼーション
- next
- nuxt
- playwright
- prettier
- react
- reactnative
- tensorflowjs
- tools
- typescript
- wasm
- websocket
- ポエム
- 開発環境
サーバー
その他
イコラブのニュースをスクレイピングする!
はじめに
どうもスクレイピング芸人です.
今回はいこらぶのニュースを取得します.
今回はいこらぶのニュースを取得します.
=LOVE NEWS
https://equal-love.jp/news/
これ->
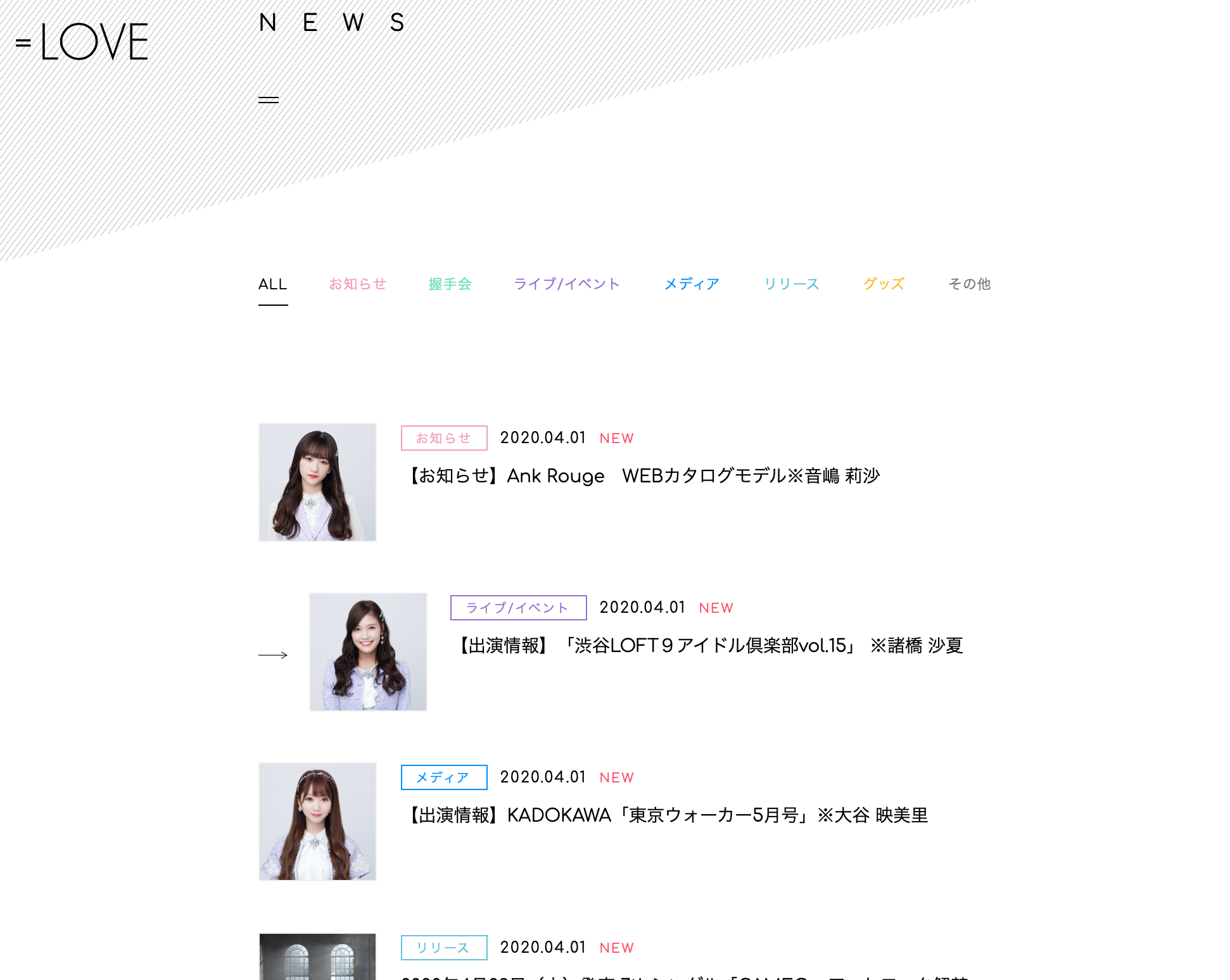
前回と同様, ソースコードを確認します.
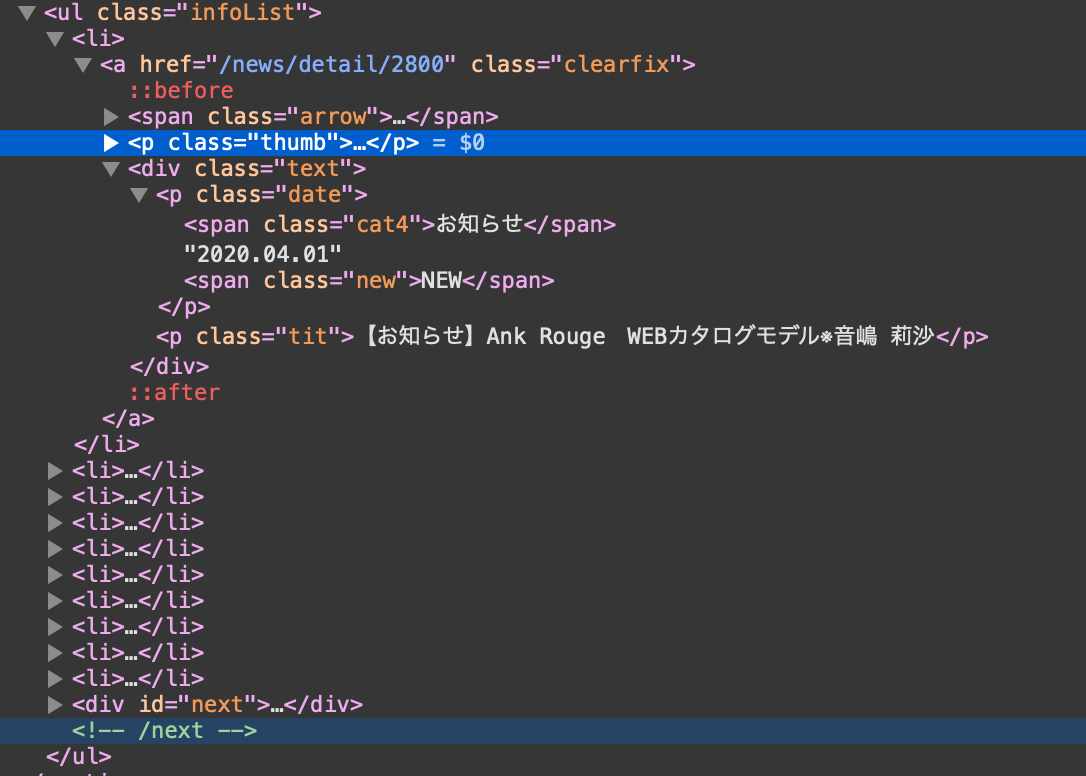
おぉ、なんと良心的なソースコード..
日向坂とは大違い.. と思いきや, "日 付 の と こ ろ"
いやお前なんでタグで囲まれてないねん.. めんどくせぇ..
日向坂とは大違い.. と思いきや, "日 付 の と こ ろ"
いやお前なんでタグで囲まれてないねん.. めんどくせぇ..
でもおれはあきらめんぞぉ
技術選定
今回もaxiosとcheerioを使ってスクレイピングします.
ソースコード
import axios from "axios";
import cheerio from "cheerio";
interface news {
date: string;
category: string;
body: string;
}
const scraping = async (): Promise<string> => {
try {
const response = await axios.get("https://equal-love.jp/news/");
return response.data;
} catch (err) {
console.log(err);
return "";
}
};
const analysis = (result: string): news[] => {
const $ = cheerio.load(result);
console.log($("title").text());
const news: news[] = [];
$(".infoList li").map((i, element) => {
const body = $(element).find(".tit").text();
const category = $(element).find("span:first-child").text();
const date = $(element).find(".date").text().replace(/[^0-9\.]/g, "");
const object: news = {
date: date,
category: category,
body: body.trim(),
};
news.push(object);
});
return news;
};
export const main = async () => {
const result = await scraping();
const news = analysis(result);
console.log(news);
};
// メインの実行
(async () => {
await main();
})();解説
大体前回といっしょですね.
違うのはgetリクエストになったところですかね.
あ、さっき言ってた日付のところは魔法(正規表現)を使いました.
正規表現よくわかんないけど動いたからヨシ!
違うのはgetリクエストになったところですかね.
あ、さっき言ってた日付のところは魔法(正規表現)を使いました.
正規表現よくわかんないけど動いたからヨシ!
他には span:first-child 使ってカテゴリー取得したりしてます.
実行結果
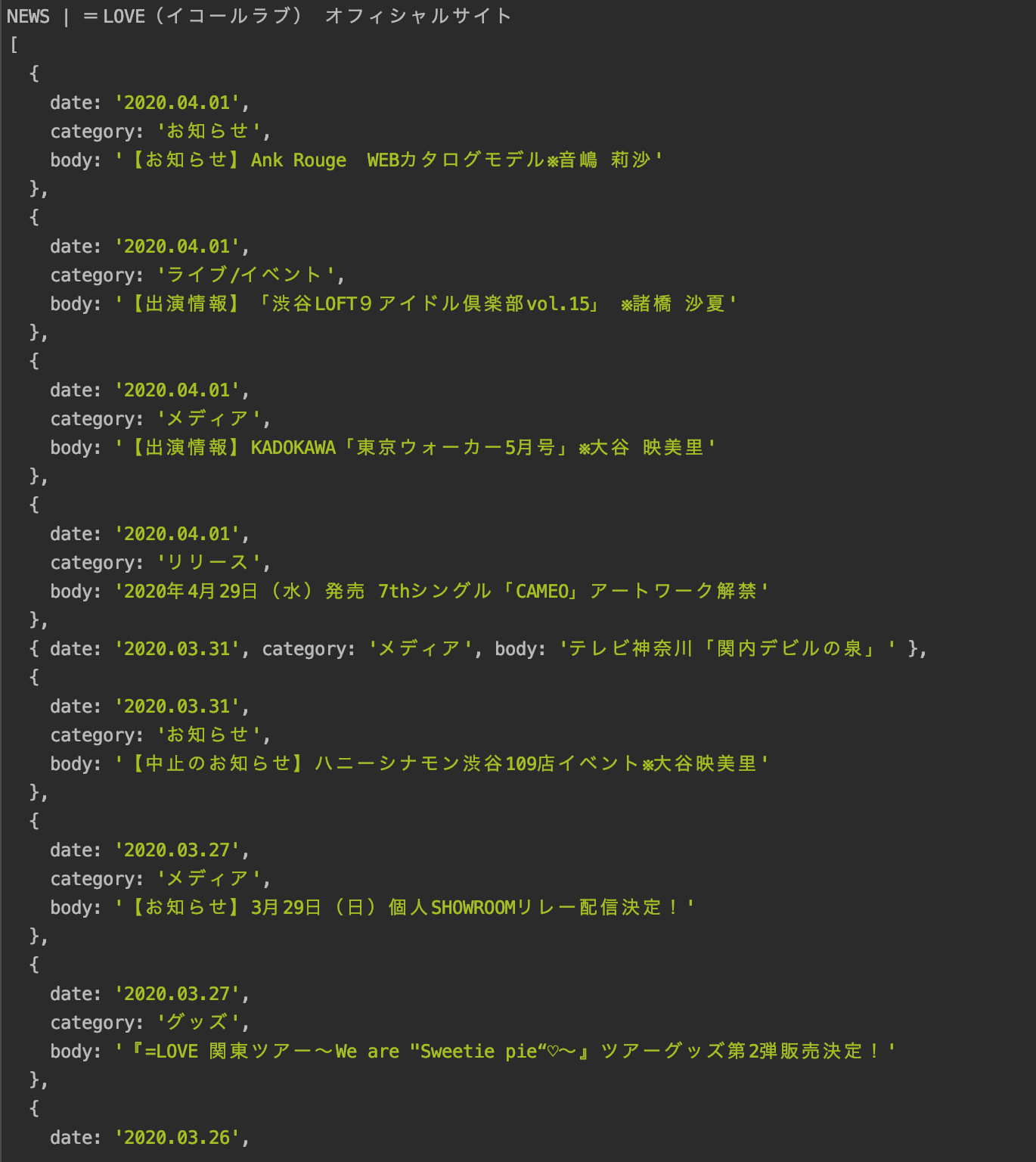

よきね.
でもちょっと少なくね?
でもちょっと少なくね?
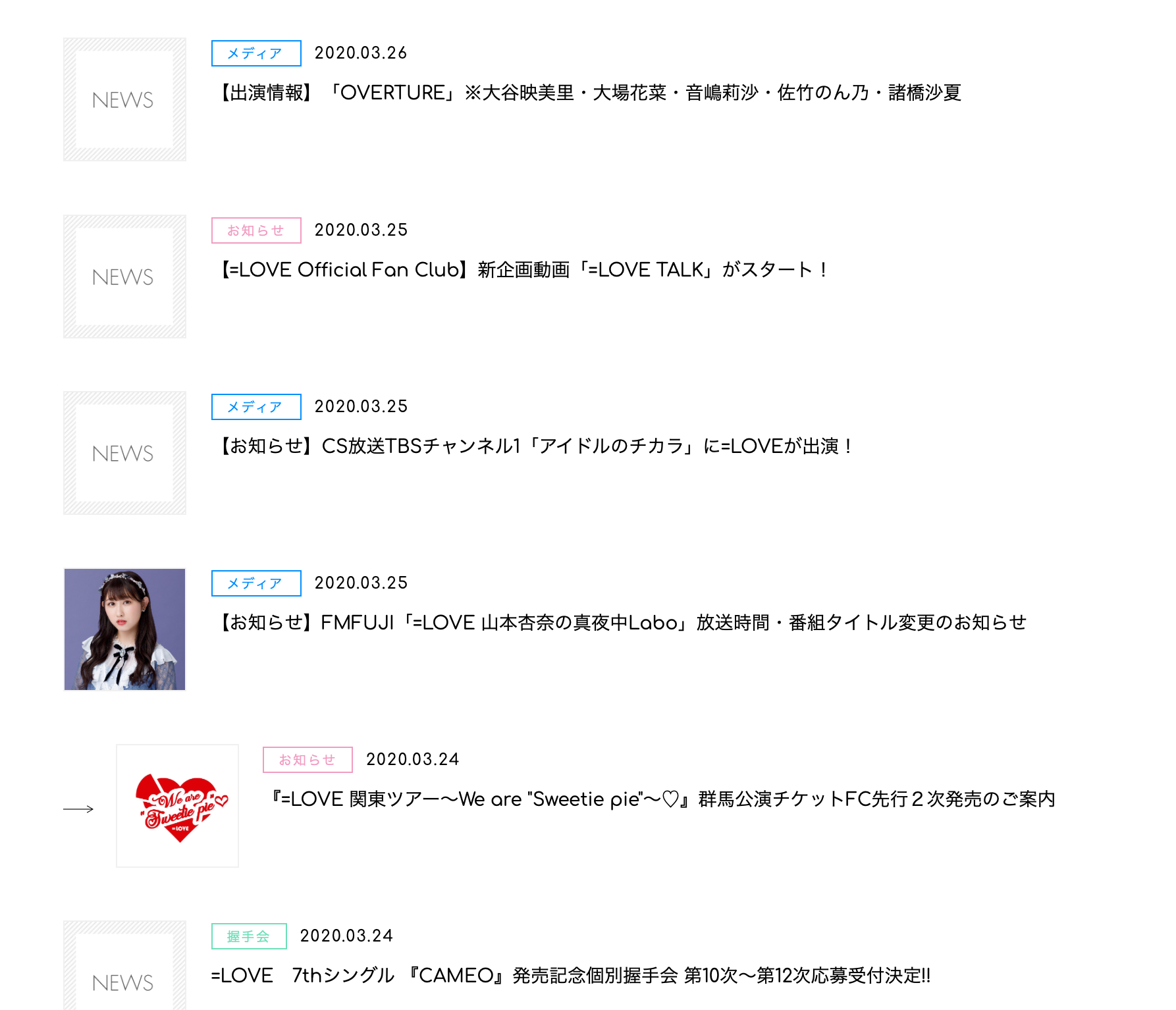
サイトには表示されているのに..
解決策
そう、このサイト 一定以上スクロールするとオートロードされるやつです.
ではどうやってこれを取得するのか..
ではどうやってこれを取得するのか..
多分、外部となんか通信してるでしょ!っていうノリで探し出します.
あった. 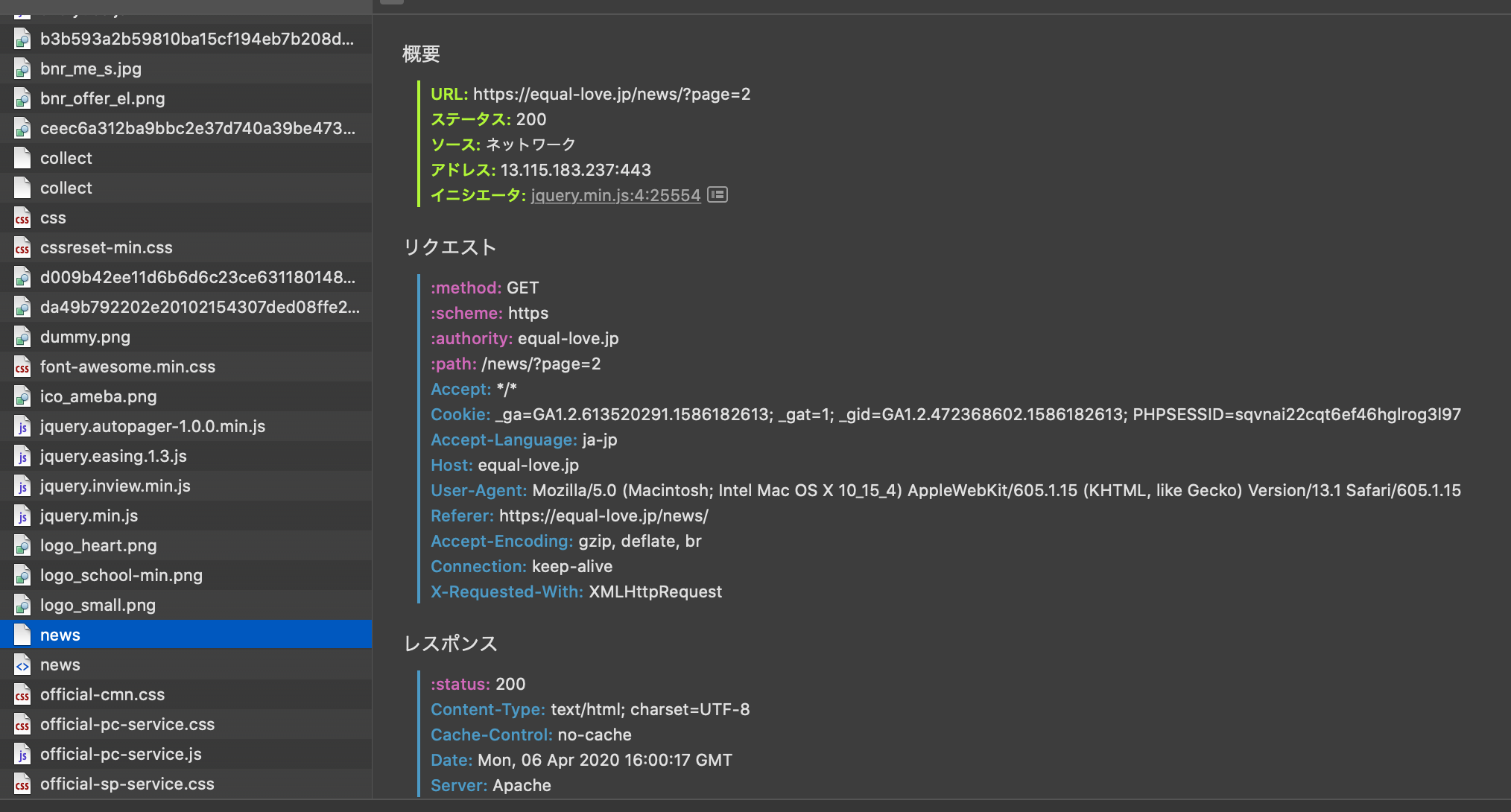
pageパラメータをつけてgetリクエスト送ってますね.
見つけたのでもう勝ちです.
あとは実装するだけ.
見つけたのでもう勝ちです.
あとは実装するだけ.
ソースコード修正部分
const scraping = async (i: number): Promise<string> => {
try {
const response = await axios.get("https://equal-love.jp/news/", {
params: {
page: i,
},
});
return response.data;
} catch (err) {
console.log(err);
return "";
}
};
export const main = async () => {
const news = [];
for (let i = 1; i < 11; ++i) {
const result = await scraping(i);
const tmp = analysis(result);
news.push(tmp);
}
console.log(news);
};解説
とりあえず1~10ページ分取得するコードです.
axiosのパラメータに指定します.
axiosのパラメータに指定します.
実行結果
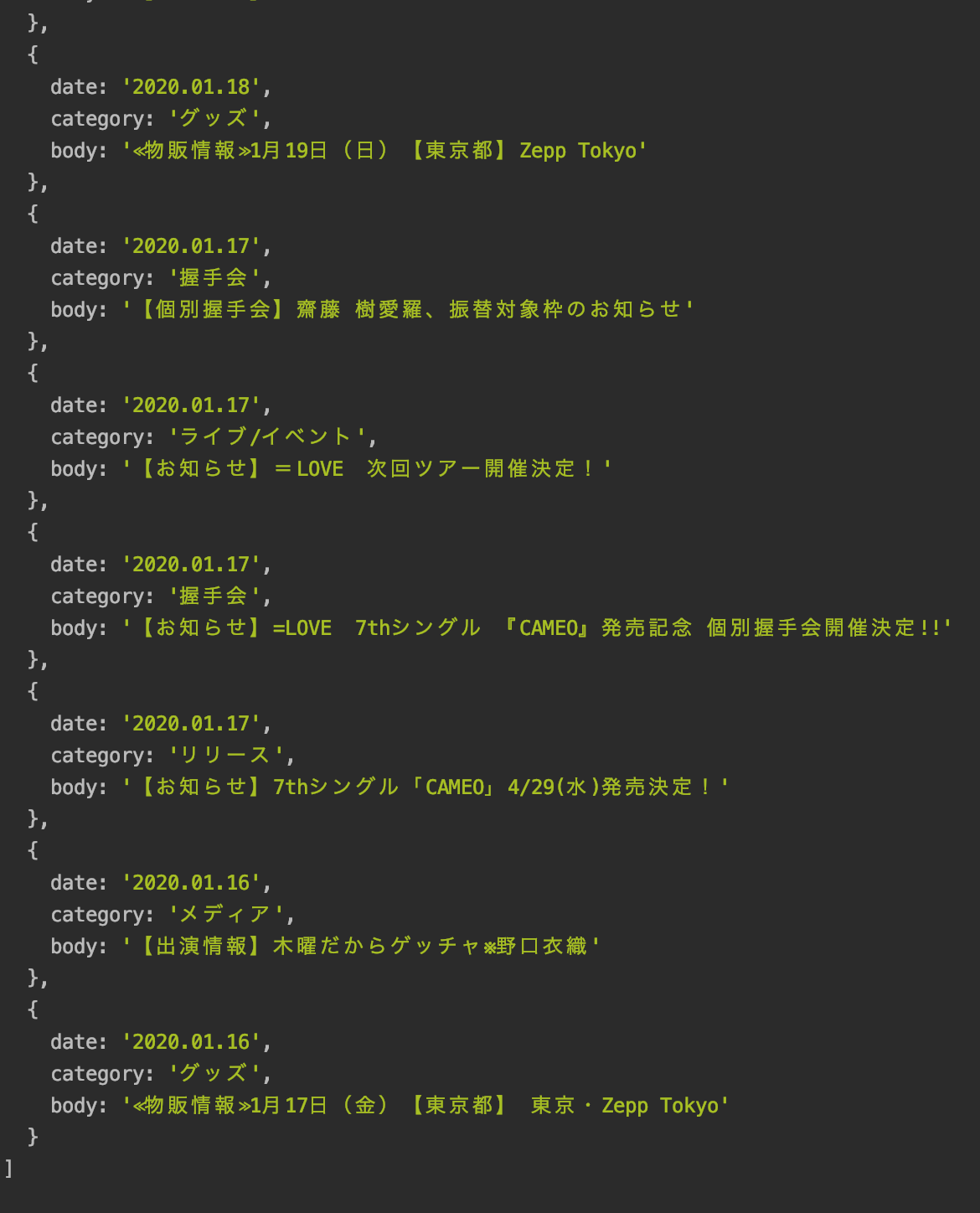
見事に1月まで取得できました.
余裕ですね(
余裕ですね(
おわりに
スクレイピング楽しいね!!
Thanks you for reading.