ウェブフロント
- angular
- corewebvitals
- editorconfig
- gatsby
- hls
- html
- javascript
querySelectorAllで取得した要素は配列ではないらしい
JavaScript 配列内のオブジェクトの更新ってどうする?
デバッグ関数とかnullチェック関数をutil/index.tsにおいとけば楽なことに今頃気づいた。
ブラウザからジャイロセンサーを使ってみる
JS 画像のアップロード、プレビュー機能を実装
「数値から各桁の値を取り出す処理」って言われたら数学的な処理が一番に思い浮かぶけど、JSならそんなことなかった。
Callback時代の関数をPromise化する
個人的実装されてほしいECMA Script Proposal
JavaScriptのprototypeを使う
音声をなみなみさせる
AudioWorkletとAudioWorkletProcessorを使って音声のビジュアライゼーション
- next
- nuxt
- playwright
- prettier
- react
- reactnative
- tensorflowjs
- tools
- typescript
- wasm
- websocket
- ポエム
- 開発環境
サーバー
その他
推しのブログをスクレイピング
はじめに
ブログとかみてるとスクレイピングしたくなりますね(なりません).
なので今回は推しのブログをスクレイピングします.
なので今回は推しのブログをスクレイピングします.
推しのブログ (乃木坂46) http://blog.nogizaka46.com/momoko.oozono/?p=1
これ->
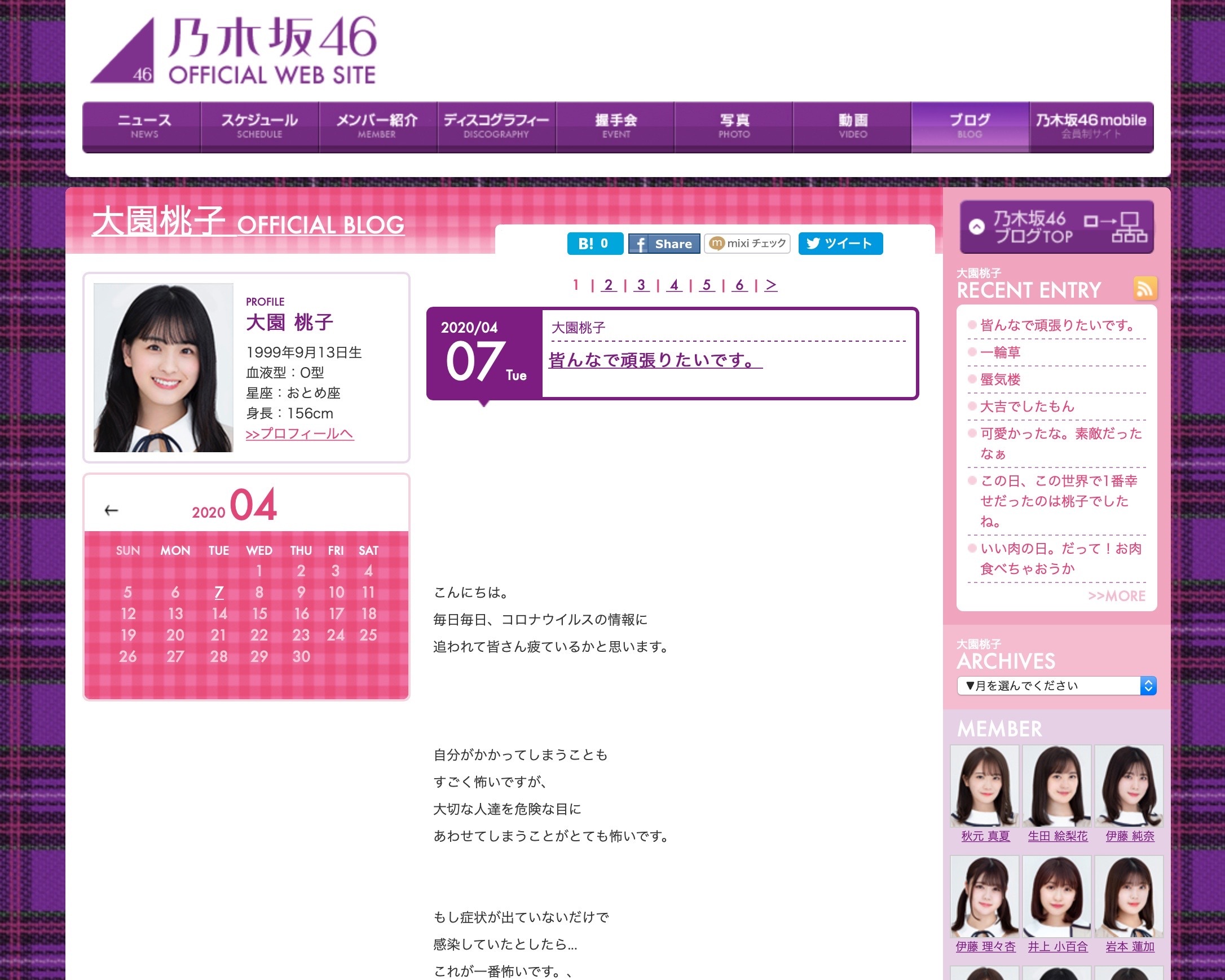
最初にソースコードの確認をします.
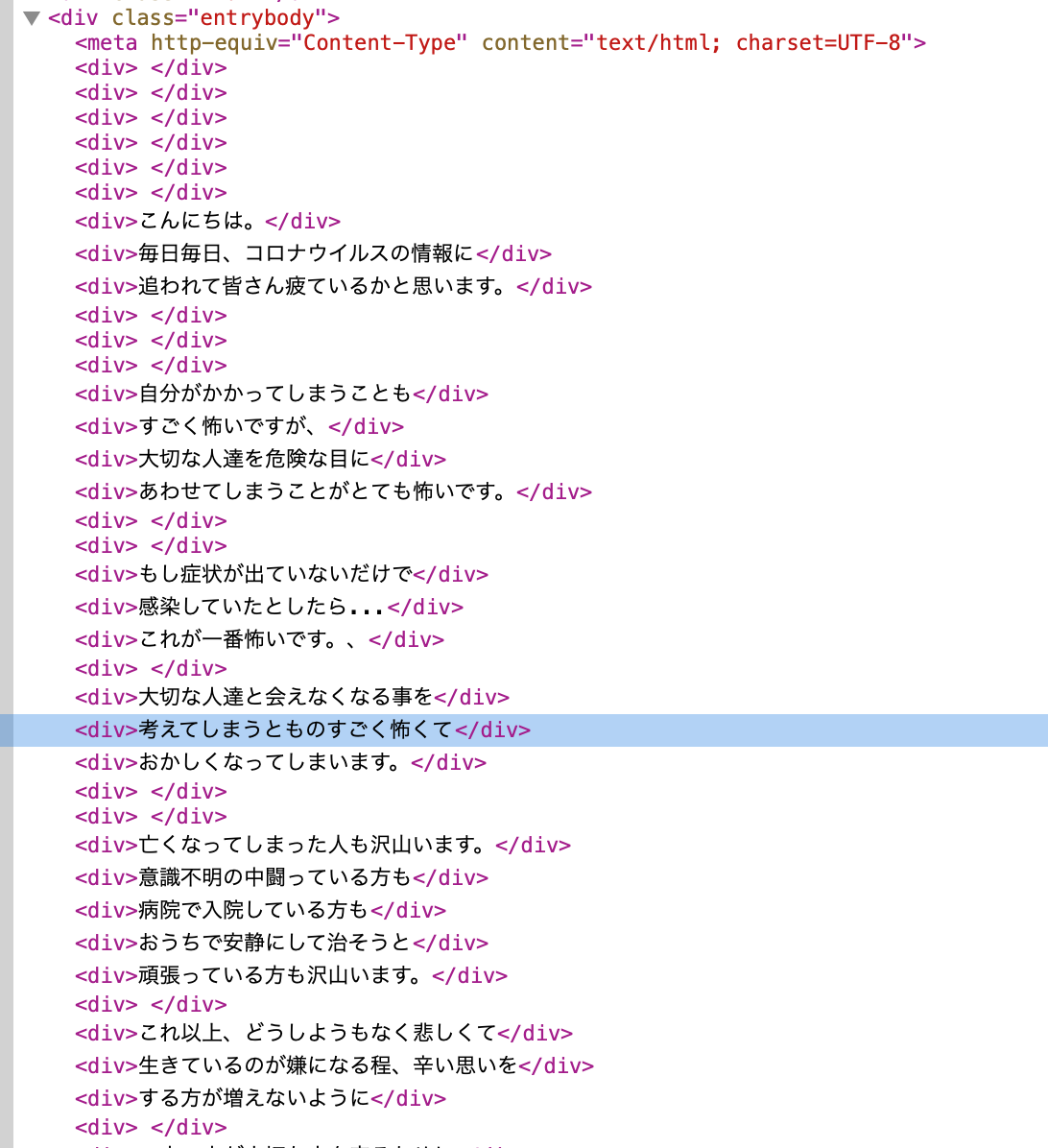 優しいソースコードですね..
優しいソースコードですね..
entrybodyってクラスのところにあるみたいです.
ただ, 推しが空白文字や改行を多用するのでそこらへんの処理が必要そうです.
優しいソースコードですね..entrybodyってクラスのところにあるみたいです.
ただ, 推しが空白文字や改行を多用するのでそこらへんの処理が必要そうです.
コード
import axios from "axios";
import cheerio from "cheerio";
import * as fs from "fs";
const scraping = async (i: number): Promise<string> => {
try {
const response = await axios.get(
"http://blog.nogizaka46.com/momoko.oozono/",
{
params: {
p: i,
},
},
);
return response.data;
} catch (err) {
console.log(err);
return "";
}
};
const analysis = (result: string) => {
const $ = cheerio.load(result);
console.log($("title").text());
const body: string[] = [];
$(".entrybody").map((i, element) => {
body.push($(element).text().replace(/[\r\n\t\s]/g, ""));
});
return body;
};
export const main = async () => {
const news = [];
for (let i = 1; i <= 6; ++i) {
const result = await scraping(i);
const tmp = analysis(result);
news.push(tmp);
}
const article = news
.flat()
.reduce((prev, current) => prev + current + "\n", "");
fs.writeFile("article.txt", article, (err) => {
if (err) console.log(err);
else console.log("write success");
});
};
// メインの実行
(async () => {
await main();
})();解説
コードの流れはいつもと同じです.
fsモジュールを使って結果をtxtファイルに書き出すようにしました.
fsモジュールを使って結果をtxtファイルに書き出すようにしました.
先ほど言っていた改行や空白文字は正規表現を使って削除します.
感覚で書いても動かなかったのでちゃんとお勉強しました..
\r, \t, \n、\s が改行とか空白で[]で1文字でも一致したら~です.
感覚で書いても動かなかったのでちゃんとお勉強しました..
\r, \t, \n、\s が改行とか空白で[]で1文字でも一致したら~です.
JavaScript 正規表現まとめ (Qiita) https://qiita.com/iLLviA/items/b6bf680cd2408edd050f
getリクエスト部分は?p=6まで存在したのでループで回してます.
flatとreduceしてるところは, 配列に配列をpushしていくのでネストが一段階深くなってしまうのを戻してから 全ての文字を結合してひとつにする感じです.
だって、ブログなのに配列じゃやだじゃん.. (これは偽でflatとかreduce使いたかっただけ)
ちなみにflatメソッドはtsconfigを少しいじらないと使えないみたいです.
ちなみにflatメソッドはtsconfigを少しいじらないと使えないみたいです.
実行結果

おわりに
いやぁ、流石にきもいね(
Thanks you for reading.